2026.01.24
DL 최적화 개념 및 방법
🦋 SKALA: SK AX AI Leader Academy
1. DL 모델 최적화 개념/방법
- 주어진 조건이나 제약 내에서 최상의 결과를 얻도록 과정이나 방법을 조정/개선하는 것
- 자원, 시간, 비용 등을 최소화 하거나 효율성, 효과성 등을 최대화 하는 것이 주된 목표
- ML에서의 최적화
- 모델이 정확하게 예측하고 좋은 성능을 발휘하도록 조정
- 새로운 데이터에 대해 잘 작동할 수 있도록 모델 개선
- 학습 속도를 높이고 자원을 효율적으로 사용
- DL에서의 최적화
- 특정 함수의 값을 최대, 최소화 시키는 최적의 파라미터 조합을 찾는 문제
- 실제값과 예측값의 차이가 최소가 되는 방향으로 최적화 수행
- Loss function
이제 손실 함수(오차)의 값을 최소화하는 최적의 파라미터를 찾는 방법과 관련 개념들을 알아보자
2. Gradient Descent, Learning Rate
Gradient Descent
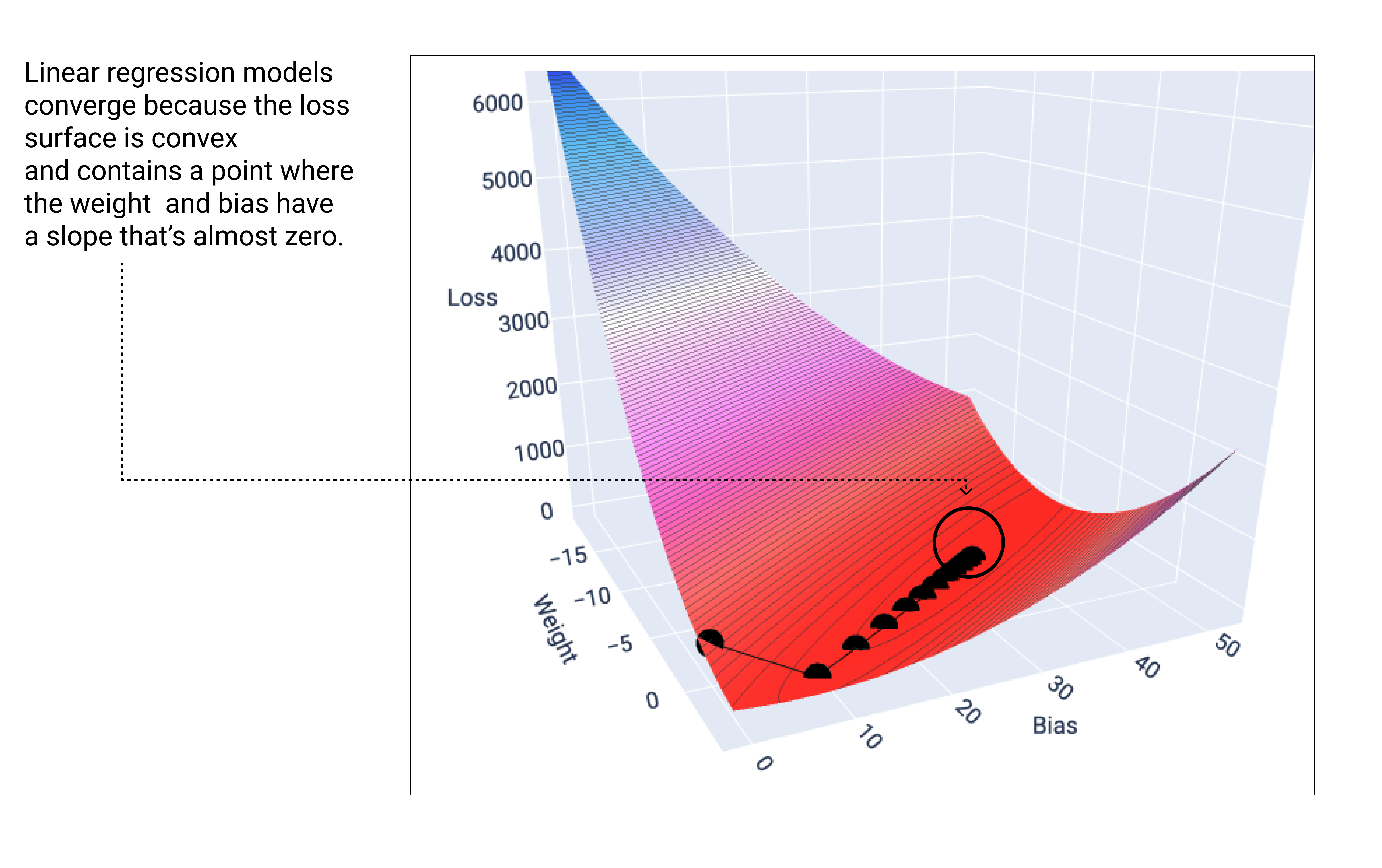
- Optimizer 초기 버전, 함수의 기울기를 이용하여 함수의 최소값을 찾으려고 함
- 오차(
Loss)를 줄이기 위해 기울기(Gradient)를 따라 아래로 내려감
- 산꼭대기에서 안대를 쓰고 골짜기(
최저점)를 찾아 내려가는 상황을 상상해 보자… 발을 내디딜 때마다 경사가 아래쪽인 방향을 찾는 행위 자체가 경사하강법임
- 목표
- 오차가 최소가 되는 지점(
Global Minimum)을 찾는 것
- 원리
- 현재 위치에서 기울기를 잼
- 기울기가 양수(+)면 왼쪽으로, 음수(-)면 오른쪽으로 이동하며 가장 낮은 골짜기를 찾아감
- 한계점
- 중간 계곡(
local minimum)에 빠질 수 있음
- 출발 위치에 민감
- 즉, 항상 정답으로 가는 것은 아님…
Learning Rate
- 얼마나 크게 움직일까?
- 경사하강법으로 방향을 정했을 때, 한 번에 얼마나 큰 보폭으로 이동할지 결정하는 값
- 사람이 직접 설정해줘야 하는 하이퍼파라미터
- 보폭의 중요성
너무 작으면 개미 걸음으로 내려가는 것 → 목표까지 도달하는 데 시간이 너무 오래 걸림너무 크면 → 보폭이 너무 큼 → 바닥을 지나쳐 반대편 벽으로 튀어 올라갈 수 있음
Gradient Descent 과 Learning Rate
$$W_{new} = W_{old} - \eta \times \frac{\partial E}{\partial W}$$
- $\frac{\partial E}{\partial W}$ (기울기): 경사하강법이 알려주는 방향과 경사도
- $\eta$ (학습률): 그 방향으로 얼마나 갈지 곱해주는 보폭
| 구분 |
경사하강법 (Gradient Descent) |
학습률 (Learning Rate) |
| 역할 |
최적의 파라미터를 찾는 전략/알고리즘 |
업데이트의 크기/보폭을 조절 |
| 핵심 |
어느 방향이 오차가 가장 작아지는 길인가? |
한 번에 몇 미터씩 이동할 것인가? |
| 결정 주체 |
수학적 공식 (기울기 계산) |
사람 (하이퍼파라미터 설정) |
| 잘못될 경우 |
길을 못 찾거나 엉뚱한 곳에 갇힘 |
시간 오래 걸리거나 목표를 지나침 |
3. Forward/Backward-propagation
- 순전파 (Forward-propagation)
- 데이터를 입력받아 신경망 층을 거쳐 예측값(Output)을 내놓는 과정
- 문제를 풀어서 답을 내는 과정
- 역전파 (Backward-propagation)
- 출력층에서 발생한 오차를 입력층 방향으로 거꾸로 전파하며, 각 가중치($W$)가 오차에 기여한 정도(기울기)를 계산하는 과정
- 누가 얼마나 틀렸는지 점수를 매기는 계산원
- 미분의 연쇄 법칙(Chain Rule)을 이용해 복잡한 층 사이의 기울기를 효율적으로 계산함
- 쉽게 설명하면
- 시험을 보고(순전파), 채점을 한 뒤(오차 계산), 틀린 문제들을 보며 어느 단원 공부가 부족했는지 거꾸로 짚어가는 과정
- 한계점
- 층이 너무 깊어지면 뒤로 갈수록 기울기가 사라지는 기울기 소실(
Gradient Vanishing) 현상이 발생할 수 있음
- 그래서 ReLU 같은 활성화 함수가 필요함
4. Optimizer
- 정의
- 역전파를 통해 계산된 기울기를 바탕으로, 실제로 가중치($W$)를 어떤 방식으로 업데이트할지 결정하는 알고리즘
- 경사하강법(GD)에서 시작하여 성능을 개선해 온 다양한 버전들이 존재함
- 발달 과정
GD: 모든 자료를 검토해 방향을 찾음 (느림)SGD: 일부만 보고 빠르게 판단하여 이동 (시간 단축)Momentum: 가던 방향의 관성을 이용해 더 빠르게 이동RMSProp: 상황(기울기의 크기)에 맞춰 보폭을 유연하게 조절Adam: **Momentum(방향성) + RMSProp(보폭 조절)**의 장점만 합침
Adam Optimizer (가장 대중적인 선택)
- 핵심 개념: 방향은 기억하고(
Momentum), 속도는 상황에 맞춰 조절(RMSProp)함
- 특징
- 각 파라미터마다 최적의 학습률을 자동으로 설정
- 지형이 울퉁불퉁해도 더 빠르고 흔들림 없이 최저점으로 수렴함
- 쉽게 이해하기
일반 GD: 안대 쓰고 발밑의 경사만 보고 한 발씩 내딛는 초보 등산객Adam: 이전 경로의 방향과 본인의 피로도까지 고려해 균형을 잡으며 빠르게 뛰어 내려가는 베테랑 등산객
Adam Optimizer의 작동 흐름
- 현재 기울기 계산: 지금 발밑이 얼마나 가파른지 확인
- 1차 모멘텀 계산: 지금까지 내려온 길을 종합해 속도와 방향 정하기 (관성)
- 2차 모멘텀 계산: 길이 얼마나 울퉁불퉁했는지 누적으로 기록 (적응형 학습률)
- 업데이트: 넘어지지 않도록 균형을 잡으며 최적의 보폭으로 빠르게 내려가기
| 구분 |
일반 경사하강법 (GD) |
Adam Optimizer |
| 방식 |
현재 위치의 경사만 보고 이동 |
이전 경험(방향+속도)을 기억하며 이동 |
| 속도 |
비교적 느림 |
매우 빠름 |
| 안정성 |
작은 골짜기에 빠지기 쉬움 |
울퉁불퉁한 지형에서도 효과적 |
| 학습률 |
고정된 보폭 사용 |
상황에 따라 보폭을 자동으로 조절 |
5. Gradient Vanishing, Exploding
- 정의
- 역전파 과정에서 기울기(
Gradient)의 크기가 층을 거칠수록 너무 작아지거나 혹은 너무 커지면서 학습이 제대로 이루어지지 않는 현상
Gradient Vanishing
- 현상
- 기울기가 레이어를 거칠수록 점점 작아져 0에 수렴하게 됨
- 따라서 초기 레이어들이 거의 학습되지 않아 모델 성능이 하락함
- 원인
- 주로 Sigmoid, Tanh 활성화 함수 사용 시 발생
- 역전파 과정에서 작은 기울기 값이 계속 곱해지기 때문임
- 해결
ReLU 활성화 함수 사용(양수 영역 기울기 일정)Batch Normalization 적용
Gradient Exploding
- 현상
- 기울기가 레이어를 거칠수록 지나치게 커져 가중치 업데이트가 너무 크게 일어나고,
- 모델이 최적값에 수렴하지 못하고 발산하는 현상
- 원인
- 신경망이 매우 깊거나 가중치 초기화가 잘못된 경우 발생함
- 해결
Gradient Clipping 을 통해 기울기가 임계값을 넘지 않도록 제한- 즉, 임계값을 넘으면 그냥 해당 값으로 제한하는 방식
6. Dropout
- 정의
- 은닉층(Hidden Layer)의 뉴런을 학습 과정에서 무작위로 골라 삭제(비활성화)하며 학습하는 기법
- 효과
- 특정 뉴런에만 의존하는 현상을 방지하여 모든 뉴런이 골고루 학습하게 유도
- 결과적으로 모델이 훈련 데이터에 너무 익숙해지는 과적합을 방지하고 성능을 높임
- 주의사항
훈련(Training) 단계 뉴런을 무작위로 선택하여 학습에서 제외평가(Testing) 단계 모든 뉴런에 신호를 전달하여 학습된 결과를 확인해야 함
7. DL 의 목표
$$y = x_1W_1 + x_2W_2$$
- 수식의 의미
공부할 값 ($x$ : 정해진 값) 입력 데이터(Feature)공부 시킬 값 ($W$ : 가중치) 정답과 가까워지도록 학습을 통해 계속 업데이트해야 할 파라미터공부 결과 ($\hat{y}$) 모델이 예측한 값오차/손실 ($y$ : 채점) 실제 정답과 예측값 사이의 차이
- 무엇을, 언제까지 공부시키나?
가중치 학습
- 정답($Y$)과 최대한 가까워지도록 Gradient Descent을 사용하여 가중치($W$)를 수정
학습 중단
- 훈련 데이터에만 너무 특화되는 과적합이 발생하기 직전까지 학습
- 드롭아웃이나 조기 종료(Early Stopping) 기법 활용
- 학습 데이터가 너무 크다면?
배치(Batch) / 미니배치(Mini-batch)
- 데이터를 한꺼번에 학습시키기 어려울 때, 작은 묶음으로 나누어 학습시킴
에폭(Epoch)
- 전체 학습 데이터를 한 번 모두 사용했을 때의 단위
- 여러 번 반복(Multi-Epoch) 학습을 통해 데이터의 특징을 더욱 정교하게 파악 가능
🦋 SKALA: SK AX AI Leader Academy