Electronic Brain
Perceptron
ADALINE
XOR Problem
Backpropagation
SVM (Support Vector Machine)
Deep Neural Network
AlexNet (CNN)
GAN & RNN/LSTM
AlphaGo
Transformer
BERT & GPT-3
ChatGPT & Diffusion
Multi-modal & Agentic AI
Input)와 정답(Label/Output)이 모두 적힌 문제집을 푸는 것Y)을 찾기위한 학습Labeled) 보다 정답지가 없는 문제(UnLabeled)는 엄청 많을 때 사용Labeled 데이터로만 학습한 모델보다 더 좋은 성능의 모델을 만들어낼 가능성 있음Unlabeled 데이터를 함께 활용한다는 측면에서 지도 학습과 차이가 있으나, Output은 동일Input) 데이터만 제공Decision Rule: 특정 조건(질문)에 따라 데이터를 분기Data random subset: 데이터를 무작위로 샘플링하여 여러 묶음을 만듦Making random trees: 각 묶음마다 독립적인 나무를 생성Building random forest: 이 나무들을 모아 집단지성(숲)을 구축가중치 부여: 이전 단계에서 틀린 데이터에 더 큰 가중치를 주어 집중 학습반복 수행: 성능이 더 이상 좋아지지 않을 때까지 순차적으로 나무를 쌓음연산 방식 개선: XGBoost의 속도 한계를 극복하기 위해 병렬 처리 도입Leaf-Wise: 수평이 아닌 수직 방향으로 효율적인 분할 수행Maximum Margin: 그룹 간의 경계(여백)가 가장 커지도록 결정 경계를 설정Kernel Trick: 직선으로 나눌 수 없는 비선형 데이터는 차원을 높여 ‘커널’로 구분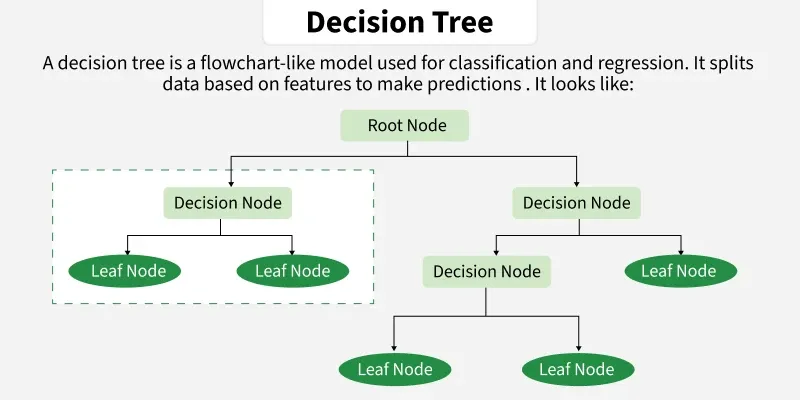
불순도가 높다 빨간 공, 노란 공, 초록 공이 한 바구니에 마구 섞여 있는 상태불순도가 낮다 한 바구니에 빨간 공만 예쁘게 모여 있는 상태Gini Index 한 집단에서 임의로 두 개를 뽑았을 때 서로 다른 공이 나올 확률Entropy 이 집단이 얼마나 어질러져 있는지 무질서를 체크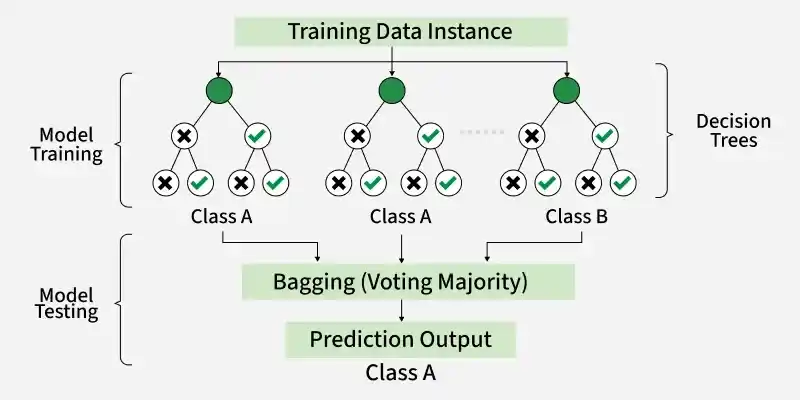
random subset 데이터 변수를 무작위로 선택하여random trees 여러 개의 트리들을 임의적으로 생성하여 각 트리들로부터 얻어질 결과가 평균 이상이 되면feature selection 최대의 정보가 반영되도록 정답을 잘 설명할 수 있는 변수를 선택하여random forest 생성된 트리들의 성능에 투표하여 모델을 정의함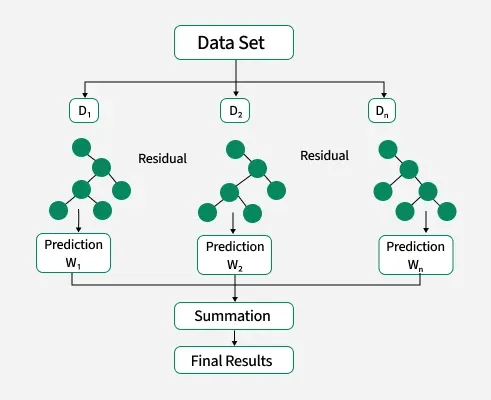
eXtreme Gradient Boosting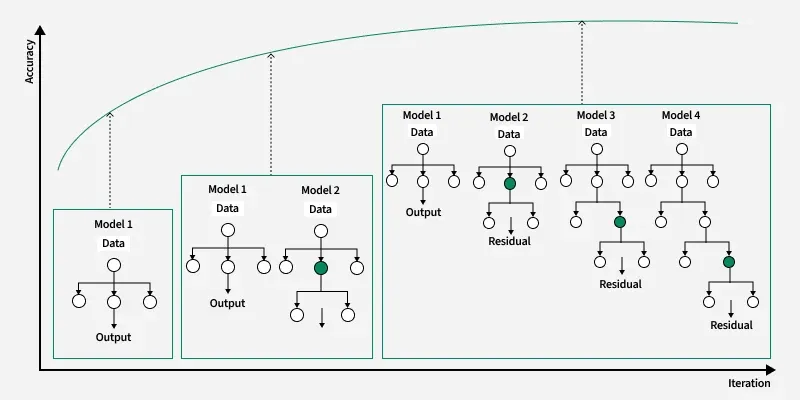
Light Gradient Boosting MachineGOSS: 데이터의 일부만 샘플링하여 계산량을 대폭 줄임EFB: 희소한 변수들을 하나로 묶어 처리 속도를 높임max_depth나 num_leaves 같은 파라미터를 세심하게 조절해야 함
Categorical Boosting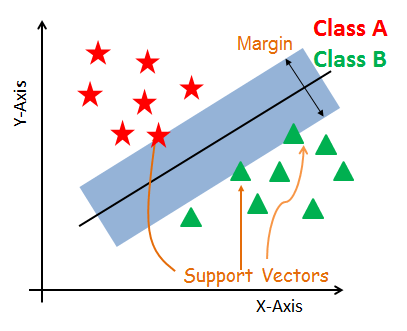
마진은 결정 경계와 가장 가까이 있는 데이터 포인트 사이의 거리를 의미함Linear, Polynomial, RBF(방사 기저 함수) 등 다양한 커널을 선택할 수 있음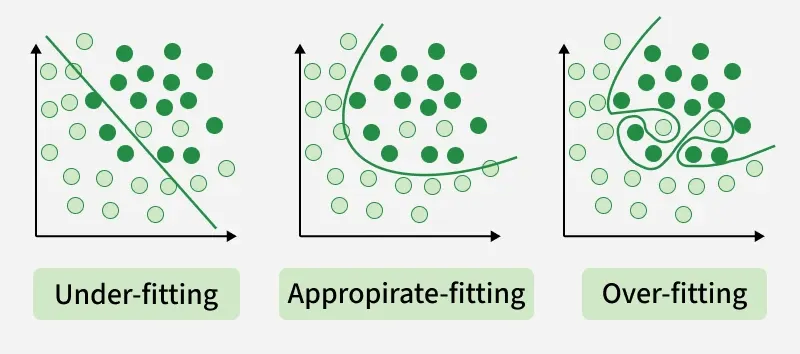
현재 상황
다시 살펴보면
이것이 곧 L2/L1
Normalizer 모든 데이터를 0~1 사이로 맞추거나Standardizer 평균 0, 표준편차 1이 되도록 조정| 계열 | ML Algorithm | 표준화 필요 여부 | 주요 이유 |
|---|---|---|---|
| Tree-Based | DecisionTree | 필요 없음 | 조건에 따른 분기 방식으로 값의 크기나 단위와 무관 |
| randomForest | 필요 없음 | 개별 트리 자체가 스케일 영향 받지 않음, 다양한 트리 조합이 더 중요 | |
| XGBoost | 필요 없음 | 트리 기반 부스팅 방식으로 크기와 단위 영향이 적음 | |
| LGBM | 필요 없음 | Leaf 중심 분할 방식으로 값의 절대적인 크기 영향이 적음 | |
| CatBoost | 필요 없음 | 역시 값의 크기 단위 영향 적음 범주형 처리도 안정적 |
|
| Kernel (거리) | SVM | 필요 | 그룹 간 경계 결정에 계산이 핵심 변수 크기 차이가 크면 특정 변수가 과하게 영향을 미침 |
| Penalty (회귀) | LASSO | 필요 | 가중치 절대값의 합(L1)에 패널티 적용 변수 특성 크기가 다르면 큰 값을 가진 특성에 패널티가 쏠림 |
| Ridge | 필요 | 가중치 제곱합(L2)에 패널티 적용 변수 크기 차이가 크면 작은 값의 특성은 무시될 수 있음 |