2026.02.01
DL-AlexNet & ResNet
🦋 SKALA: SK AX AI Leader Academy
1. AlexNet & ResNet
- AlexNet GPU 기반 딥러닝의 서막을 알림
- ResNet: 더 깊게, 더 멀리 층을 쌓을 수 있게 만든 현대 CNN의 표준 (2015년)
2. AlexNet
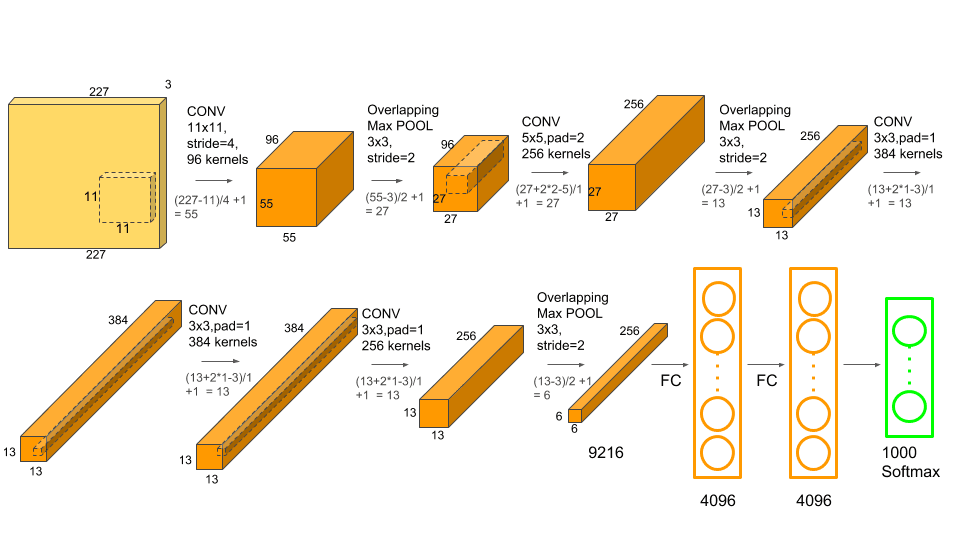
- 2012년 ILSVRC 대회에서 압도적인 성적으로 우승하며 GPU 기반 딥러닝의 서막을 알림
- 핵심 기술적 특징
ReLU 활성화 함수 사용: Sigmoid보다 훨씬 빠른 학습 속도 구현Dropout 과적합을 방지하기 위해 뉴런의 일부를 무작위로 끔GPU 병렬 연산 당시 메모리 한계로 인해 두 개의 GTX 580 GPU에 네트워크를 나누어 학습Data Augmentation 데이터를 뻥튀기하여 모델의 일반화 성능을 높임
- 한계
- 8개 층(Layer) 정도로 구성되었으며, 이보다 더 깊게 쌓으려 하면 오히려 성능이 떨어지는 문제에 직면함
3. Degradation Problem
- 왜 층을 더 못 쌓지?
- 이론적으로는 층이 깊어질수록 더 복잡한 특징을 배울 수 있어야 함
- 하지만 실제로는 층이 깊어질수록 **기울기 소실(Vanishing Gradient)**과 연산 복잡도 때문에 오히려 학습이 안 되고 에러가 높아지는 현상이 발생
- 이를 ‘망이 퇴화한다’는 의미에서
Degradation Problem이라고 부름
4. ResNet

- 기존의 정보를 그대로 다음 층으로 전달하면 어떨까? 라는 단순하지만 혁신적인 아이디어
- 각 층의 출력을 다음 층으로 직접 전달하는 Skip Connection 추가해 문제 해결
- Residual Learning (잔차 학습)
- 단순히 $H(x)$를 학습하는 것이 아니라, $H(x) - x$ (잔차)를 학습하는 방식
- $H(x) = F(x) + x$ 라는 수식으로 표현됨
- Skip Connection (Shortcut)
- 입력을 출력에 직접 더해주는 경로를 추가
- 미분 시 $x$의 미분값인 1이 살아남아, 아무리 층이 깊어져도 기울기가 앞단까지 잘 전달됨
- 공부한 내용($F(x)$) 뿐만 아니라 교과서 내용($x$)도 같이 시험장에 가져가는 것
5. AlexNet vs ResNet 한눈에 비교
| 구분 |
AlexNet (2012) |
ResNet (2015) |
| 층의 개수 |
8개 |
152개 이상 |
| 핵심 아이디어 |
ReLU, Dropout, GPU 병렬화 |
Skip Connection (잔차 학습) |
| 활성화 함수 |
ReLU |
ReLU (주로 Batch Norm과 함께) |
| 파라미터 효율 |
층에 비해 파라미터가 매우 많음 |
깊이에 비해 파라미터가 효율적임 |
| 역사적 의의 |
딥러닝의 실용성 증명 |
초거대 신경망 학습의 가능성 제시 |
6. Bottleneck Architecture (ResNet의 전략)
- ResNet-50 이상의 깊은 모델에서는 연산량을 줄이기 위해 Bottleneck 구조를 사용함
- 1x1, 3x3, 1x1 Convolution을 차례로 배치하여 차원을 줄였다가 다시 늘림
- 이는 마치 모래시계처럼 데이터를 꽉 조였다가 풀어주는 과정으로, 성능은 유지하면서 연산 비용을 획기적으로 낮춤
7. 통합 핵심 정리
AlexNet이 **“딥러닝도 이미지를 잘 인식할 수 있다”**는 가능성을 열었다면ResNet은 **“지름길(Shortcut)만 있다면 층은 무한히 깊어질 수 있다”**는 해답을 제시함- 오늘날 우리가 사용하는 대부분의 고성능 모델은 ResNet의 Skip Connection 개념을 기본적으로 탑재하고 있음
🦋 SKALA: SK AX AI Leader Academy