
Long-term Memory 먼 과거의 정보를 보존하는 능력이 탁월함Gating Mechanism 3개의 게이트를 통해 정보의 흐름을 정밀하게 제어Gradient Flow 셀 상태(Cell State)를 통해 기울기 소실 문제를 획기적으로 완화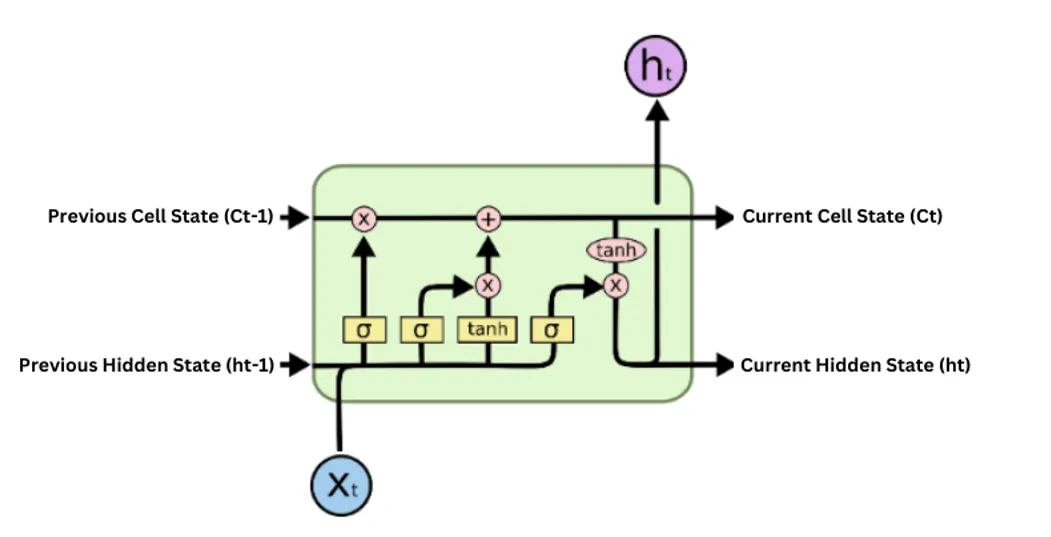

| 구분 | RNN | LSTM |
|---|---|---|
| 기억 능력 | * 과거 정보를 짧게 기억 | * RNN 보다는 과거 정보를 길게 기억 가능 |
| 구조 | * 현재 상태와 입력값을 받아 Hidden State(현재 상태)를 통해 출력 * tanh 함수로 단순 계산 |
* Cell State(기억 저장소, 장기 상태)와 Gate를 활용하여 상태 출력 * Forget/Input/Output Gate로 정보 조절 * 계산량이 많고, RNN보다 학습 시간이 길어짐 |
| 한계점 | * 어느 정도 과거를 기억하지만, 긴 시퀀스 학습 어려움 (Vanishing Gradient) * 시간 순서 의존 $\rightarrow$ 연산 속도 느림 (병렬처리 한계) |
* 계산량이 많고, 긴 시퀀스에서 목적을 달성하기 어려움 * 시간 순서 의존 $\rightarrow$ 연산 속도 느림 (병렬처리 한계) |
| 설명 | * 순간순간 정보를 이어가는 방식 | * 순간순간 정보를 이어가는 방식에 더해 * 중요한 정보를 따로 저장하는 기억 저장소(Cell)를 통해 과거 중요한 정보를 오래 활용할 수 있도록 함 |
Reset Gate와 Update Gate만 사용하며, 셀 상태와 은닉 상태를 하나로 합침Forget 필요 없는 과거는 지우고Input 중요한 현재 정보는 더하고Cell State 이 정보를 고속도로에 실어 보내어Output 다음 단계에 필요한 맥락만 출력하는 구조