🦋 SKALA: SK AX AI Leader Academy
1. 소개
컨테이너를 통해 애플리케이션을 손쉽게 패키징하고 실행할 수 있는 것은 사실이나, 현대 클라우드 기반 서비스 운영 단계에서는 여러 한계가 존재한다. 아래 한계를 보완하기 위해 여러 클라우드 아키텍처가 고안되었으며, 가장 많이 쓰이는 k8s(k8s)를 한번 알아보자.
- 컨테이너만으로 운용 시 한계
- 각 노드에서 직접 docker run 명령을 수행해야 하는 구조
- 컨테이너가 중단될 경우 수동으로 재시작해야 하는 번거로움이 존재
- 어떤 노드가 과부하 상태인지, 혹은 리소스 여유가 있는지 직접 확인 필요
2. 기저의 역사

- 1️⃣ 전통적 배포 시대
- 물리 서버 한 대 위에 여러 애플리케이션을 직접 실행
- 리소스 격리 불가 -> 특정 앱이 메모리를 독점하면 다른 앱이 죽는 간섭 현상 발생
- 이를 피하려고 서버 한 대당 앱 하나만 띄우니 자원 낭비와 비용 부담이 극심
- 2️⃣ 가상화 배포 시대
- 하이퍼바이저를 이용해 하나의 물리 CPU에서 여러 개의 VM을 실행
- VM 간의 자원 침범 불가, 독립적인 보안 환경 제공
- 하드웨어 자원을 쪼개어 쓰므로 비용 절감 및 확장성 향상
- 각 VM마다 각각 OS를 포함해야 하므로 무겁고 리소스 소모가 여전히 큼
- 3️⃣ 컨테이너 개발 시대
- OS 커널은 공유하면서 CPU, 메모리, 파일 시스템 등 프로세스 공간만 격리
- VM보다 훨씬 가볍고 빠름. 인프라 종속성을 끊어 어디서든 돌아가는 이식성 확보
- 👀 그래서 왜 컨테이너가 대세일까?
기민성 VM보다 이미지 생성이 쉽고 배포 속도가 빠름불변성 한 번 빌드된 이미지는 어디서든 동일 작동하여 안정적인 롤백 가능관심사 분리 개발자는 앱 빌드에, 운영자는 인프라 관리에 집중가시성 앱 수준의 헬스 체크와 시그널을 세밀하게 모니터링 가능환경 일관성 개발 노트북, 테스트 서버, 운영 클라우드 환경 일치이식성 OS 배포판이나 퍼블릭/프라이빗 클라우드 구분 없이 구동추상화된 관리 하드웨어가 아닌 애플리케이션 중심의 논리적 리소스 관리마이크로서비스 최적화 작고 독립적인 단위로 쪼개어 동적인 배포와 관리에 유연
3. k8s 기본 개념
- k8s는 컨테이너 운영을 자동화하기 위한 도구
- 즉, 클라우드의 OS라고 볼 수 있음
- 운영자는 단순히 이 애플리케이션을 3개 실행해줘 하면, k8s가 알아서
- 요청 SPEC에 따라 실행 요청하고 ->
controller
- 적당한 노드를 찾고 ->
scheduler
- 컨테이너를 실행하고 ->
kubelet
- 네트워크를 연결하고 ->
kube-proxy
- 상태를 주기적으로 확인하고 , 문제가 생기면 복구 ->
controller
- 즉, 선언적 시스템을 가지고 있으며, 사용자가 이런 상태를 원한다 고 선언하면 클러스터가 알아서 맞춰주는 방식으로 동작함
4. k8s 선언적 관리의 3요소
- 선언적 관리를 위해서 3가지 요소가 존재 (
Manifest, Object, Resource/Kind)
- 이 3가지 요소는 여러 명칭 또는 정의로 표현되곤 함
- k8s 시스템에서 상태를 나타내는 모든 엔티티를 통칭하는 의미로 k8s Objects…
- 개념적인 묶음의 의미로 선언적 API 모델…
- 기술적으로 k8s 리소스 모델…
1️⃣ Manifest
- 사용자가 작성하는 YAML 파일
- 나는 nginx Pod 3개를 원해 등의 의도를 담은 설계도
- 실제로 클러스터에 존재하는 무언가가 아니라, 파일일 뿐
2️⃣ Object
- k8s가 관리하는 모든 관리 대상의 총칭
Pod, deployment, service 등 모두 Object의 종류- desired state(원하는 상태)와 actual state(현재 상태)를 동시에 가짐
- 생성 과정
- Manifest를 기반으로
kubectl apply 하면,
apiserver 가 검증 후 etcd에 저장됨- etcd에 저장된 시점부터 클러스터에 실제로 등록된 상태가 됨
3️⃣ Resource / Kind
- Resource: apiserver가 제공하는 API 엔드포인트 경로 (/api/v1/Pods)
- Kind: Object의 타입 이름 (Pod, Deployment, Service…)
- YAML의
kind: Pod에서 쓰는 바로 그 값이 Kind
| 용어 |
비유 |
설명 |
| Manifest |
설계도 (Blueprint) |
종이에 적힌 계획 (YAML 파일) |
| Object |
실제 건물 (Instance) |
땅 위에 실제로 지어진 구체적인 건물 |
| Resource / Kind |
건물 유형 (Type) |
아파트인지, 상가인지 구분하는 기준 |
5. k8s 실행의 물리적/논리적 구조

5.1. Node
Node란?
- 실제 물리적인 서버 혹은 VM으로, Pod에게 CPU/메모리 같은 HW 자원을 제공
- 하나의 Node 위에 여러 개의 Pod가 올라갈 수 있음
- Node는
Master Node, Worker Node 로 구분됨
Master Node와 Worker Node
- Master Node
- 전체 클러스터를 관리하고 명령을 내리는 관리 서버
- 이때
Control Plane 란 클러스터를 관리하기 위한 SW 요소 집합 존재
- Worker Node
- 마스터 노드의 명령을 받아 Pod를 실행하고 트래픽을 처리하는 실행 서버
kubelet
- 각 노드에서 실행되는 핵심 에이전트
- 전달받은 Pod 명세를 확인하여 컨테이너의 정상 실행 유지 관리
kube-proxy
- 노드마다 실행되는 네트워크 프록시로, 트래픽이 올바른 Podf로 전달되도록 제어
- 각 노드에서 호스트의 네트워크 규칙(iptables/IPVS 등)을 관리
ControlPlain
- Master Node에 설치된 k8s의 의사결정 기구
kube-api-server
- 쿠버네티스 클러스터의 중앙 창구
- 모든 구성 요소가 서로 통신하기 위해 거쳐야 하는 유일한 통로
- REST API를 통해 클러스터의 상태를 조회하거나 변경
etcd
- 클러스터의 현재 상태와 데이터가 기록되는 Key-Value 저장소
kube-scheduler
- 새로운 Pod가 생성되었을 때 어느 노드에 배치할지 결정
- 각 노드의 자원 상태, 정책, 라벨 등을 고려하여 최적 실행 위치 지정
kube-controller manager
- 클러스터의 상태를 감시하고 유지하는 제어 루프들의 집합
- 노드 다운 대응 / 파드 개수를 유지 등 원하는 상태를 만드는 작업 수행
cloud-controller manager
- 클라우드 서비스 제공자(AWS, GCP 등)의 API와 쿠버네티스를 연결
- 클라우드 상의 로드 밸런서 생성이나 스토리지 연결 등 인프라 종속적인 작업을 처리
5.2. Pod
Pod란?
- 컨테이너 실행의 최소 단위
- 하나 또는 그 이상의 컨테이너를 감싸는 바구니
- k8s는 컨테이너를 직접 관리 X -> Pod 단위 관리 (이동/삭제)
- 보통 하나의 Pod에 한 개의 어플리케이션을 가동함
- 네트워크 공유
- Pod 사이 NAT Gateway 존재 X
- Pod 내 모든 컨테이너는 동일한 IP, Port 사용
- Pod 내 모든 컨테이너 간 통신은 Localhost 기반
- 강결합
- Pod에 정의된 Volume 또한 모든 컨테이너가 공유 가능
- 컨테이너간 파일교환도 가능
- 또한 항상 함께 배포/종료
- 컨테이너 재시작 != Pod 재생성
- 노드에서의 실행은 컨테이너 단위
- 컨테이너 사망 -> kublet이 컨테이너 재시작
- Pod 삭제 시 새로운 Pod 생성
- IP 불안정
- Pod 재생성시 IP 변경 -> Pod IP 직접 호출은 금물
- 즉, 서비스로 소통해야하는 이유임
Pod의 LifeCycle
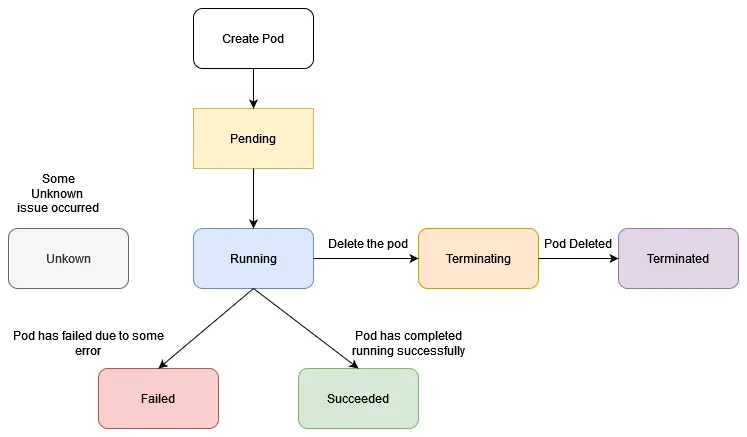
- Pod의 라이프사이클
Pending (대기)
- Pod가 클러스터에 승인되었지만, 아직 실행 준비가 덜 된 상태
- 어느 노드에 배치할지 결정하는 중(Scheduling)이거나…
- 컨테이너 이미지를 다운로드(Image Pull)하는 중이거나…
Running (실행 중)
- Pod가 노드에 배치되었고, 모든 컨테이너가 생성됨
- 적어도 하나 이상의 컨테이너가 실행 중이거나 시작/재시작되는 과정에 있는 상태
Succeeded (성공)
- Pod 내의 모든 컨테이너가 일을 완벽히 마치고 정상 종료된 상태
Failed (실패)
- Pod 내의 컨테이너 중 하나라도 비정상적으로 종료되었거나…
- 시스템에 의해 강제로 종료된 상태
Unknown (알 수 없음)
- 어떤 이유에서인지 Pod의 상태를 확인할 수 없는 상태
- 보통 워커 노드와 마스터 노드 사이의 통신이 끊겼을 때 발생함
- Pod의 생성과 삭제의 과정
Create Pod
- 사용자가 YAML(Manifest)을 통해 생성 명령을 내린 직후
Delete the Pod (Terminating)
- 사용자의 삭제 명령 -> 즉시 삭제되는 것 X
- 따로 자원 정리 시간을 가짐
Terminating
- 실행 중인 프로세스를 안전하게 종료하기 위해 신호를 보내고 대기 중인 상태
Terminated
- 모든 정리가 끝나고 클러스터에서 완전히 자취를 감춘 상태
5.3 Container
Container란?
- 격리된 프로세스
- 소스 코드와 실행 환경을 담은 격리된 프로세스
- 실제 웹 서버나 DB 같은 Application이 돌아가는 본체
- 반드시 Pod 라는 묶음 안에서만 존재
- 네트워크 공유
- Pod 사이 NAT Gateway 존재 X
- Pod 내 모든 컨테이너는 동일한 IP, Port 사용
- Pod 내 모든 컨테이너 간 통신은 Localhost 기반
PID 1
- 리눅스 시스템에서 가장 먼저 실행되는 부모 프로세스
- 즉, 컨테이너가 시작될 때 가장 먼저 실행되는 프로세스가 PID 1
- PID 1은 자신에게 들어오는 시그널을 처리하고, 자식 프로세스들에게 전달해야 함!
- “문제가 실제로 발생하는 시나리오”
- 1️⃣
command: ["sh", "-c"] / args: ["python3 app.py"]
- 2️⃣ 이러면
sh 이 PID 1 / 실제 우리 앱 python3 은 자식 프로세스 됨
- 그렇다면 내부에서 벌어지는 일을 보자
- 1️⃣ 사용자가
kubectl delete pod를 실행
- 2️⃣ kubelet이 컨테이너에게 SIGTERM 시그널 보냄
- 3️⃣ SIGTERM이 PID 1(sh) 에게 전달
- 4️⃣
sh 등의 쉘 프로세스는 기본적으로 SIGTERM 무시
- 5️⃣ 실제 앱인
python3는 종료 신호가 온 지도 모르고 계속 작동 중
- 6️⃣ 30초를 기다리던 k8s는 SIGKILL 을 날림
- 결국 정상 종료가 안되는 과정에서 ->
- 해결 방법
- 내 앱이 직접 PID 1이 되게 만들자
Exec Form 사용
- Dockerfile이나 YAML에서 쉘을 거치지 않게 작성
exec 명령어 사용
- 쉘 스크립트를 써야 한다면 마지막 실행 시
exec 사용
Tini 같은 Init 프로세스 사용
- tini 같은 전문 신호 전달 요원을 PID 1로 세우기도 함
Init Contianer
- 메인 컨테이너가 실행되기 전, 준비 작업을 위해 먼저 실행되는 특수한 컨테이너
- 순차적 실행
- 여러 개의 Init Container가 있다면, 설정된 순서대로 하나씩 실행됨
- 앞선 컨테이너가 성공적으로 종료되어야 다음 컨테이너가 실행됨
- 완료 필수
- Init Container는 반드시 **성공적으로 종료(Exit Code 0)**되어야 함
- 만약 실패하면 k8s는 성공할 때까지 Pod를 재시작함
- 앱 컨테이너 차단
모든 Init Container가 성공하기 전까지는 실제 메인 앱 컨테이너는 절대 시작 X
- 언제 사용할까?
- 메인 앱 이미지에 포함하기엔 보안상 위험하거나, 용량이 크거나, 복잡한 로직을 처리할 때
의존성 체크 DB 준비를 Init Container가 체크 -> 확인 후 앱을 띄우기 가능보안/인증 앱 이미지에는 없는 민감한 도구나 인증서를 가져와서 공유 볼륨에 저장 가능환경 설정 복잡한 설정 파일을 생성하거나 동적으로 내려받는 작업을 수행 가능
4. k8s Manifest 유형

- 결국 Manifest 라는 설계도를 기반으로 여러 Object가 만들어짐
- 각각의 요소들을 조금 더 상세하게 알아보자!
4.1 Service
- k8s에서 Pod를 네트워크 상에 노출시키는 방법
- 클러스터에 존재하는 IP 주소
4.2 Deployment
- 여러 개의 Pod를 관리하기 위한 상위 리소스
- Pod 배포에 대한 원하는 규격을 선언
4.3 Ingress
- 2026.03.28 기준 k8s에서는 Ingress 대신 Gateway 사용을 권장함

- Ingress (오브젝트)
어떤 도메인(foo.com)으로 들어오면 어떤 서비스로 보내라- 위 규칙을 적어놓은 선언문(YAML)
- Ingress Controller (구현체)
- 그 규칙을 실제로 읽어서 트래픽을 배달해주는 소프트웨어(Nginx, ALB 등)
- 역할
- HTTP/HTTPS 요청을 도메인이나 경로에 따라 서로 다른 서비스로 연결
- 단순한 IP 기반 연결이 아니라, URL 주소를 보고 길을 찾아주는 우체국 같은 역할
- 여러 개의 서비스를 운영할 때, 각 서비스마다 비싼 외부 로드밸런서를 만들 필요 없이 Ingress 하나로 모든 서비스를 관리할 수 있어 비용과 관리가 효율적
- 라우팅 규칙 (Routing Rules)
- 하나의 입구로 들어와도 주소에 따라 목적지가 달라짐
ex) kubia.example.com/kubia → kubia 서비스로 연결ex) foo.example.com → foo 서비스로 연결
- 동작 방식
- 우선 클라이언트가 도메인 주소로 요청을 보냄
- Ingress Controller가 이 요청의 호스트명과 경로를 확인
- 설정된 규칙(YAML)에 따라 적절한 Service를 선택하고, 해당 서비스 뒤에 있는 Pod들에게 트래픽을 전달
4.4 ConfigMap
- 환경변수/설정파일을 컨테이너 실행 시 주입하기 위한 리소스
4.5 Namespaces
- k8s에 자신의 application을 배포했을 때 사용되는 리소스를 위한 논리적 구분
- Namespaces vs 노드 (논리 vs 물리)
- Namespaces (논리적 울타리)
- k8s라는 거대한 운동장에 그어놓은 가상의 금
- 여기서부터 여기까지는 A팀이 쓰는 리소스라고 이름표를 붙여주는 관리 단위
- 노드 (물리적 장소)
- 실제로 전기가 들어오고 CPU가 돌아가는 서버(기계)
- 왜 노드를 넘나들 수 있을까?
- 사용자가 production이라는 Namespaces에 Pod 10개를 띄우라고 명령하면,
- 스케줄러는 이 Pod들이 어느 Namespaces 소속인지 상관하지 않고, 클러스터 전체 노드 중 자원이 남는 곳을 찾아가며 Pod를 골고루 배치
- 그 결과, 1번 노드에도 production Namespaces의 Pod가 있고, 2번 노드에도 production Namespaces의 Pod가 있게 됨
4.6 Secret
- 클러스터의 비밀 금고
- 비밀번호, OAuth 토큰, ssh 키와 같은 민감한 정보를 저장하고 관리하기 위한 Object
- 기본적으로 데이터는 Base64로 인코딩되어 저장되나, 암호화가 아니므로 보안 설정을 추가하는 것이 좋음
4.7 Job
- 하나 이상의 Pod를 생성하고, 지정된 개수의 Pod가 성공 종료될 때까지 실행을 보장하는 Object
- Deployment는 Pod가 죽으면 살려내어 24시간 떠 있게 만들지만, Job은 작업이 끝나서 Pod가 정상 종료(Succeeded)되면 다시 살리지 않고 작업을 마침
- 주요 용도 ->
데이터베이스 마이그레이션 (DB 스키마 업데이트), 배치 작업 (매일 밤 로그 분석 등), 백업 및 복구 작업
5. Reference
