2026.03.18
Docker Container
🦋 SKALA: SK AX AI Leader Academy
1. 소개
로컬과 서버의 OS가 다르고, 설치된 언어의 버전이 꼬이거나 라이브러리 경로가 어긋나면 본격적인 개발을 시작하기도 전에 진이 다 빠지곤 한다. 도커 컨테이너는 바로 이러한 환경의 파편화 문제를 해결하기 위해 등장했다. 핵심은 실행 환경의 표준화이다. 어디서든 동일한 환경을 보장해주는 도커 컨테이너의 내부 동작 방식과 실제 활용법을 정리해보고자 한다.
2. 기저의 역사
컨테이너 기술의 탄생부터 도커, 그리고 현재의 클라우드 네이티브 생태계까지
2.1. 컨테이너의 탄생
- 컨테이너의 개념은 리눅스/유닉스 시스템의 프로세스 격리 기술에서 출발함
- 1979년 chroot
- 특정 프로세스의 루트 디렉토리를 변경하여 파일 시스템을 격리하는 최초의 시도
- 2000년대 초반 (FreeBSD Jails, Solaris Zones)
- 단순 파일 시스템 격리를 넘어 네트워크, 사용자 등을 독립적으로 관리하는 가상 환경의 개념이 정립
- 2008년 LXC (Linux Containers)
- 리눅스 커널의 Cgroups(자원 제한)와 Namespaces(자원 격리)를 조합하여 현대적인 컨테이너 기술의 기틀을 마련
- 하지만 사용법이 매우 복잡하여 전문가들만 사용하는 기술에 머무름
2.2. VM과 컨테이너의 공존
- 2010년대 초반까지 IT 인프라의 주인공은 VMware나 가상 머신(VM)
- 당시 컨테이너는 가볍지만 위험하고 다루기 힘든 기술로 치부
- 따라서 주로 대규모 인프라를 직접 운영하는 거대 기업 내부에서만 사용됨
| 구분 |
가상 머신 (VM) |
초기 컨테이너 (LXC 등) |
| 격리 |
하드웨어 수준 격리 (하이퍼바이저)로 안전 |
호스트 커널을 공유하여 보안 우려 |
| 범용성 |
Windows 호스트에서 Linux 실행이 가능 |
호스트 OS와 컨테이너 OS가 동일해야함 |
| 관리 |
VMware 등 성숙한 관리 솔루션이 존재 |
CLI 기반으로 설정이 매우 복잡하고 파편화 |
| 이식성 |
가상 디스크가 너무 커서 옮기기 어려움 |
환경이 조금만 달라져도 실행이 안 되는 경우가 많았음 |
2.3. Docker의 등장
- Image와 레이어
- 파일 시스템을 레이어 단위로 쌓고 이를 이미지로 박제/관리
- Dockerfile
- 인프라 설정을 코드로 관리(IaC)할 수 있게 하여 재현성을 용이하게 관리
- Docker Hub
- 전 세계 사람들이 이미지를 공유하는 중앙 저장소를 만들어 인프라 확장
- 표준화
- 복잡한 리눅스 커널 명령어를
docker run 등으로 단순화
2.4 Docker 그 이후
- 도커가 시장을 장악한 이후, 기술의 독점을 막고 표준화를 위해 OCI 설립
- 이제는 도커 외에도 다양한 목적에 특화된 툴들이 등장
- Kubernetes
- 수천 개의 컨테이너를 관리하는 사실상 업계 표준
- Podman
- 도커 데몬 없이 동작하며 루트 권한이 필요 없는 보안에 특화된 컨테이너 엔진
- containerd & CRI-O
- 도커의 무거운 기능들을 걷어냄
- 컨테이너 실행이라는 본연의 기능에만 집중한 경량 런타임
- 현재 쿠버네티스의 기본 엔진으로 주로 쓰임
- Buildah & Skopeo
- 이미지 빌드, 관리 작업을 도커 없이 수행할 수 있게 해주는 특화 도구들
3. VM과 컨테이너
- VM (Virtual Machine)
- 하드웨어 수준의 가상화
- 하이퍼바이저 위에 Guest OS를 통째로 올리기 때문에 시스템 자원을 많이 차지하고 부팅 속도가 느림
- Docker Container
- OS 레벨의 가상화
- Host OS의 커널을 공유하면서 프로세스 단위로 격리된 환경을 제공
- 별도의 OS를 띄우지 않으므로 훨씬 가볍고 실행 속도가 빠름
| 구분 |
VM |
Docker Container |
| 구조 |
HW 레벨 가상화 (Guest OS 필수) |
OS 레벨 가상화 (Host OS 커널 공유) |
| 속도 |
부팅 및 실행이 느림 (분 단위) |
프로세스 실행 수준으로 매우 빠름 (초 단위) |
| 무게 |
GB 단위, 무겁고 자원소모⬆️ |
MB 단위, 가볍고 효율적임 |
4. Docker
4.1. Docker 핵심 개념
- Dockerfile
- Dockerfile은 이미지를 만들기 위한 설계도로, 명령어로 이미지의 Layer를 형성
- Docker 이미지
- 애플리케이션 실행에 필요한 코드, 라이브러리, 환경 설정을 모두 담아놓은 템플릿
- Docker 컨테이너
- Docker 이미지를 메모리에 올려 실행시킨 격리된 프로세스, 실제 서비스가 동작하는 공간
- Docker 볼륨
- 컨테이너가 삭제되더라도 데이터를 보존하기 위해 host와 연결하는 독립적 저장 공간
- Docker 네트워크
- 격리된 컨테이너들이 서로 통신하거나, 외부와 연결해주는 가상의 통신망
4.2. Dockerfile
| 명령어 |
의미 및 역할 |
FROM |
이미지를 생성할 때 기반이 되는 Base Image 지정 |
RUN |
이미지 빌드 과정에서 명령어를 실행하여 새로운 레이어를 생성 |
COPY |
호스트에 있는 파일이나 디렉토리를 이미지 내부의 경로로 복사 |
ADD |
COPY와 유사 -> 압축 파일 해제, 파일을 다운로드하는 기능 등 |
WORKDIR |
이후 실행될 명령어가 실행될 작업 디렉토리를 설정 |
ENV |
이미지 내부에서 사용할 환경 변수를 설 |
EXPOSE |
컨테이너가 실행될 때 외부로 노출할 포트 번호 지정 |
CMD |
컨테이너가 실행될 때 기본으로 실행될 명령어 |
ENTRYPOINT |
컨테이너 실행 시 반드시 실행되어야 하는 명령어 지정 |
4.3. Docker 내부 아키텍처와 작동 방식
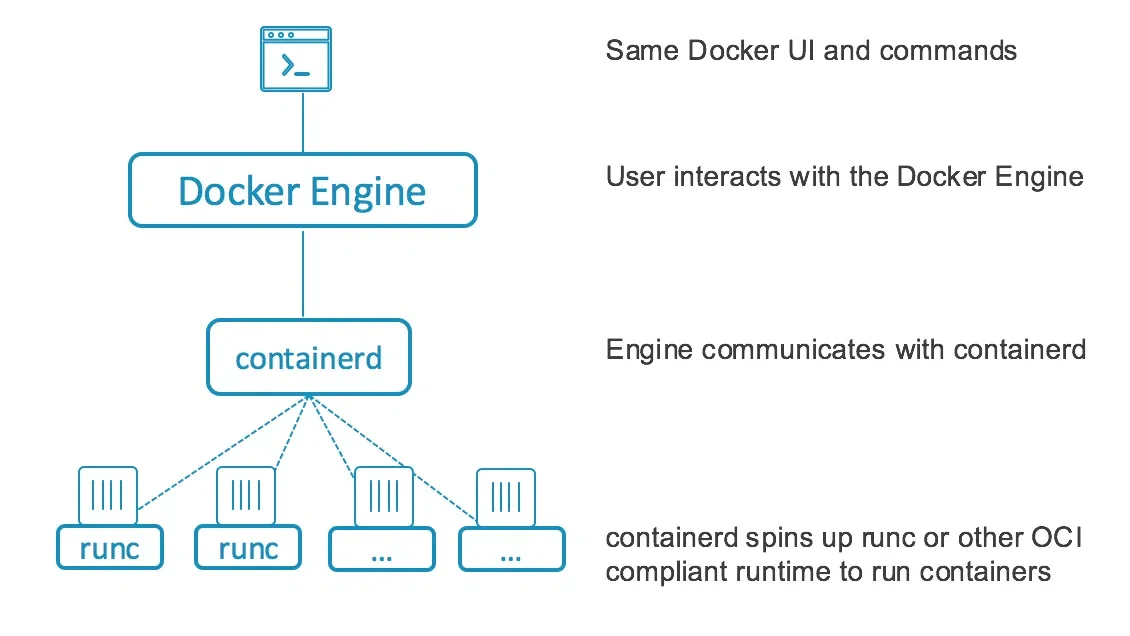
- dockerd (Docker Daemon)
- 도커 엔진의 핵심! 사용자의 요청을 받는 API 서버 역할
- 이미지 관리, 네트워크 설정, 볼륨 관리 등 고수준 작업을 처리
- 실제 컨테이너 생성 작업은 스스로 X,
containerd 에게 요청을 넘김
- containerd
- 컨테이너의 생명주기를 관리하는 상위 수준 런타임
- 이미지 전송, 스토리지 관리, 컨테이너 실행 및 네트워크 관리를 담당
- 실질적인 컨테이너 프로세스 실행을 위해
containerd-shim을 생성
- containerd-shim
containerd와 실제 컨테이너 사이의 중간 다리 역할runc가 컨테이너를 생성한 후 바로 종료될 수 있게 도와줌- 컨테이너의 표준 입출력(I/O)과 로그, 종료 상태를 유지하는 역할
- runc
- OCI 표준을 따르는 저수준 컨테이너 런타임
- 리눅스 커널의 기능을 통해 실제 컨테이너 프로세스를 생성
Namespace (격리) 와 Cgroups (자원 제한) 기능
- 컨테이너를 만들고 프로세스를 실행시킨 뒤, 자신은 바로 종료
실행 흐름 요약
- 사용자가 명령을 내리면
dockerd가 이를 수신한다.
dockerd는 containerd에게 컨테이너 생성을 요청한다.containerd는 containerd-shim을 띄우고 runc를 호출한다.runc는 운영체제 커널 기능을 이용해 컨테이너를 만들고 사라진다.- 결과적으로 컨테이너 프로세스는
containerd-shim에 의해 관리되며 안정적으로 돌아간다.
지방 축제 부스를 예시로 다시 정리해보자
- 1️⃣ dockerd (시청 / 인허가 부서)
- 사용자의 요청을 받아
이곳에 부스를 지어도 되는지 검토 하고 허가증을 발급
- 부스 도면(이미지)을 확인하고 총괄 담당(
containerd)에게 연락
- 2️⃣ containerd (총괄 담당)
- 전체 공사 일정을 관리하고 인력을 배치
- 필요한 자재(이미지 레이어)를 현장에 운반
- 부스를 실제로 올릴 기술자(
runc)를 부름
- 공사가 끝나면 현장을 관리할 경비원(
shim)을 미리 대기시킴
- 3️⃣ runc (건물 골조 기술자)
- 컨테이너라는 격리된 공간을 설계도대로 세팅하고 사라지는 전문가
- 현장에 도착해 울타리를 치고(Namespace), 전기와 물의 양을 제한하며(Cgroups)
- 이후 부스 안에 실제 작업할 사람(프로세스)을 입장시킴
- 입장이 완료되고 부스의 물리적 환경 세팅이 끝나면,
runc는 장비를 챙겨 바로 현장을 떠남
- 4️⃣ containerd-shim (축제 경비원)
runc 가 떠난 뒤, 부스에 남은 사람(프로세스)을 24시간 감시하고 보고containerd가 “그 부스 잘 돌아가나?“라고 물어보면 상황을 보고- 부스가 무너지거나(프로세스 종료) 안에 사람이 나가면 그 소식을 전함
- 특히, 시청(
dockerd)이 공사 중이어도 경비원은 자리를 지키므로 부스 안의 사람(서비스)은 안전
5. 사용 방법
간단한 파이썬 애플리케이션을 도커 환경에서 실행하는 과정을 통해 사용 방법을 알아보자
Dockerfile 작성
# 1. 베이스 이미지 지정
FROM python:3.9-slim
# 2. 호스트의 파일을 컨테이너 내부로 복사
COPY . /app
WORKDIR /app
# 3. 의존성 설치 및 앱 실행
RUN pip install -r requirements.txt
CMD ["python", "app.py"]
Docker image 빌드와 run
작성이 완료되면 터미널에서 이미지를 빌드하고 컨테이너를 띄운다.
# Dockerfile을 읽어 'my-python-app'이라는 이름의 이미지를 빌드한다.
$ docker build -t my-python-app .
# 빌드된 이미지를 백그라운드(-d)에서 포트 8080으로 연결하여 실행한다.
$ docker run -d -p 8080:8080 my-python-app
6. Q&A
Docker가 OS를 따로 설치하지 않는데, FROM 을 통해 ubuntu, apline 등을 가져오는 이유
OS를 설치하지 않는다 는 말은 커널을 포함하지 않는다는 뜻- 하지만 애플리케이션이 실행되려면 커널 외에도 다양한 시스템 라이브러리와 유틸리티가 필요함
- 모든 컨테이너는 호스트 OS의 리눅스 커널을 공유하므로, 컨테이너 내부에 커널을 또 설치할 필요가 X
- 애플리케이션은 커널 위에서 돌아가는
ls, bash, python, libc, apt 등의 라이브러리 환경이 필요
FROM ubuntu , FROM alpine 은 바로 이 환경을 제공하는 것
도커 이미지에 실제 코드가 압축되어 들어가나?
- 결론부터 말하자면 맞지만, 단순한 압축 파일이 아니라
레이어 기반의 스냅샷 형태
- Dockerfile의 각 명령어(COPY, RUN 등)는 하나의 읽기 전용 레이어를 생성
- 이 레이어들은 실제 파일 시스템의 변경 사항을 담고 있는 Diff 데이터
- 이미지를 빌드하고 푸시할 때, 각 레이어는 tar로 묶여 gzip이나 zstd 방식으로 압축되어 전송됨
- 컨테이너가 실행될 때, 이 여러 개의 압축된 레이어들을 하나로 겹쳐서 사용자에게는 하나의 통합된 파일 시스템처럼 보이게 함
- 코드는 이 레이어 중 하나에 고스란히 담겨 있음
컨테이너는 인스턴스 인가?
- 이미지는 클래스이고, 컨테이너는 그 클래스를 통해 생성된 인스턴스(객체)
- 이미지는 실행 가능한 파일과 설정의 집합일 뿐인 정적인 상태
- 이미지를 메모리에 올리고 프로세스로 격리하여 실행시킨 상태가 컨테이너
- 사실 자세히 들여다보면,
- 컨테이너는 하나의 공간이고, 인스턴스가 X
- 컨테이너는 하나의 공간이고, 그 안에 있는 프로세스가 인스턴스인 셈
- 그럼에도 그냥 인스턴스라고 부르기도 함…
컨테이너 내부에서 PID 1의 의미
- 리눅스 시스템에서 PID 1은 모든 프로세스의 조상인 Init 프로세스를 의미
- 컨테이너 환경에서 PID 1은 단순한 번호 이상의 권한과 책임을 가짐!
최상위 부모
- 컨테이너 안에서 실행되는 모든 프로세스는 PID 1의 자식
- PID 1 프로세스가 종료되면 해당 컨테이너 전체가 종료
시그널 처리의 특권과 책임
- 리눅스 커널은 PID 1에게 전달되는 시그널을 특별하게 취급
- 일반 프로세스는 커널이 기본 종료 핸들러를 제공하지만, PID 1은 개발자가 직접 시그널 핸들러를 구현하지 않으면 SIGTERM(종료 요청)조차 무시할 수 있음
- 이것이 docker stop이 가끔 10초나 걸리는 이유
좀비 프로세스 회수
- 자식 프로세스가 죽고 부모가 그 상태를 확인하지 않으면 좀비가 됨
- 정상 PID 1(systemd, tini 등)은 이 고아 프로세스들을 입양하여 자원을 해제해야 함
왜 runc는 퇴근해야 할까?
- 만약
runc가 퇴근하지 않고 컨테이너가 실행되는 내내 붙어 있다면 다음과 같은 문제가 발생
자원 낭비
- 수천 개의 컨테이너를 띄울 때마다 실행 런타임(
runc) 프로세스가 메모리를 계속 차지
결합도 문제
runc에 문제가 생기면 그와 연결된 모든 컨테이너 프로세스가 위험
- 따라서
runc는 컨테이너라는 격리된 공간을 만드는 역할만 수행하고, 완성되면 즉시 빠지는 구조를 택함
- 이후의 관리는 매우 가벼운 프로세스인
shim이 전담
Unix Domain Socket Program
- 동일한 Host 내에서 실행 중인 프로세스 간 통신을 위한 메커니즘
- TCP/IP 와 달리, UDS는 파일 시스템의 경로(예:
/var/run/docker.sock)를 주소로 사용
- 데이터가 네트워크 스택을 거치지 않고 커널 메모리 내에서 직접 복사되므로, TCP/IP 루프백 통신보다 지연 시간이 낮고 오버헤드가 적음
- 파일 시스템 권한을 통해 소켓에 접근할 수 있는 프로세스를 제어할 수 있음
폐쇄망에서 작업 시 Dns 서버의 부재
docker pull 시 도메인 기반의 이미지를 찾지 못하며, 마이크로서비스 간의 통신에서 호스트 네임을 사용 불가- 해결책
내부 DNS 구축
- CoreDNS나 Bind9 등을 활용하여 폐쇄망 전용 권한 있는 DNS 서버를 구축
Private Registry 운영
- 외부 Docker Hub 대신 망 내부에 전용 이미지 저장소(Harbor 등)를 두고 내부 DNS에 등록하여 사용
Etc Hosts 관리
- 규모가 작을 경우
/etc/hosts 파일에 수동으로 IP와 도메인을 매핑
- 그러나 보통 관리가 어려우므로 자동화 도구(Ansible 등)를 병용
OverlayFS 기반 계층 파일 시스템이란?
- 여러 개의 디렉토리를 하나의 논리적인 파일 시스템으로 통합하여 보여주는 파일 시스템의 일종이다
- 계층 구조
LowerDir
- 읽기 전용(Read-only) 레이어로, 베이스 이미지의 내용이 담김
- 여러 컨테이너가 이 레이어를 공유함
UpperDir
- 읽기-쓰기(Read-Write) 레이어
- 컨테이너에서 발생하는 모든 변경 사항(파일 생성, 수정, 삭제)이 기록됨
MergedDir
- 사용자에게 최종적으로 보이는 통합된 뷰(View)
Copy-on-Write (CoW) 메커니즘
- LowerDir에 있는 파일을 수정하려고 하면, 해당 파일을 UpperDir로 복사한 뒤 수정함
- 덕분에 원본 이미지는 손상되지 않으면서도 컨테이너마다 독립적인 상태를 유지할 수 가능
그럼에도 불구하고 VM을 사용하는 경우
- 강력한 보안 격리
- 컨테이너는 커널을 공유하므로 커널 취약점을 통한 공격에 노출 가능
- 하드웨어 수준의 완전한 격리가 필요한 경우
- 커널 종속성 및 OS 이질성
- 컨테이너는 호스트의 커널을 공유해야 한다
- 만약 Windows 전용 앱을 Linux 호스트에서 돌려야 하거나, 특정 버전의 커널 모듈이 반드시 필요한 경우
- 리소스 할당의 엄격함
- VM은 하드웨어 자원을 물리적으로 분할하여 점유함
- 다른 서비스의 자원 간섭으로부터 훨씬 자유롭고 안정적인 성능 예측이 가능
- 전통적인 엔터프라이즈 앱
- 클라우드 네이티브로 설계되지 않은 거대 Monolithic 앱
- 또는 복잡한 드라이버 설치가 필요한 소프트웨어는 VM 환경이 더 적합
7. Reference
