![Featured Image for [자료구조] List](https://programmercave.com/assets/images/Memes-Linkedlist/llmeme1.jpg)
List는 순서가 있는 데이터의 집합을 나타내는 가장 기초적인 자료구조 중 하나로, 배열(array)과의 근본적인 차이는 동적 크기 변화와 복잡한 데이터 구조를 지원하는 것이다. List는 CS에서 다양한 형태로 존재하며, 대표적으로 배열 리스트(Array List)와 연결 리스트(Linked List)가 존재한다.
std::vector<int> vec; // 동적 크기를 갖는 배열 리스트
vec.push_back(1); // 새로운 요소 추가
Array List는 연속적인 메모리 공간에 데이터를 저장하는 방식이다. 이는 인덱스를 통한 빠른 접근 속도(시간 복잡도 O(1))가 특징이지만, 크기를 미리 지정해야 하는 제약이 있다. 만약 리스트가 가득 차면 새로운 더 큰 메모리 공간을 할당하고, 기존 요소를 복사하는 과정을 거쳐야하며 이 복사 작업의 평균 시간 복잡도는 O(n)이다. 대표적인 예시로 vector를 들 수 있다.
기존 크기가 10인 Array list에 요소를 한가지 더 추가한다면, 내부적으로 11의 공간을 할당한 후, 기존 데이터를 복사한 다음 요소를 추가하는 작업이 존재한다. 물론 일반적으로는 배열 크기를 증가 시킬 때 10 -> 11 처럼 좀좀따리가 아니라 두배정도 증가시켜 추가 연산을 어느정도 제한하고 있다.
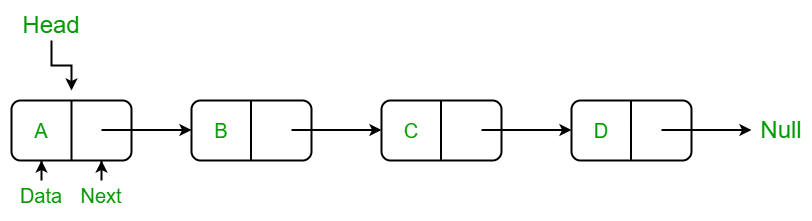
Linked List는 선형 데이터 구조로, 요소가 연속된 메모리 위치에 저장되어있지 않다. 즉, 일반 배열 처럼 a[i]의 다음 주소에 a[i + 1]이 무조건적으로 존재하지 않는다. 이 각 요소는 포인터를 사용해서 연결되어 있다.
보통 각 요소를 하나의 노드라고 칭하며, 각 노드는 데이터부분과 다음 노드의 주소가 담긴 포인터부분으로 구성되어 있다. 이때 각 노드가 다음 노드 뿐만 아니라 이전 노드의 주소도 담고 있게 만들어 활용할 수 있다. 혹은 마지막 노드가 첫번째 노드의 주소를 담고 있게 하면 Circular Linked List(원형 연결 리스트)로도 구현이 가능하다.
첫번째 노드의 주소가 담긴 HEAD의 경우 노드 구조와 별개로 포인터를 따로 두거나, 더미노드(데이터 부분이 비어있는 노드)로 만드는 방법이 존재한다.
전체적으로 활용도가 높기 때문에, Linked List를 이용해서 여러가지 자료구조를 구현할 수 있다. C++의 STL의 경우 다양한 자료구조를 Linked List를 이용해 구현해놓았다!
Linked List는 노드의 포인터를 통해 연결을 관리하기 때문에 자료의 추가나 삭제가 매우 용이하다. 그러나 자료 조회 측면에서는 배열에 비해 많은 자원이 소모된다. 배열은 인덱스를 통해 원하는 정보에 바로 접근할 수 있지만, Linked List는 조회를 위해 처음 노드부터 하나하나 순회하면서 조건에 맞는 노드를 찾아야하기 때문이다.
이러한 Linked List를 적절히 잘 사용하기 위해서라면… 응당 무언가의 연산을 가져야 할 것이다. 예를 들어 노드를 생성 한다던가 삭제한다던가. 자료구조를 구축하기 위한 연산, 자료구조에 저장된 데이터를 활용하기 위한 연산 모두 필요하다.
사실 Linked List는 42 과정의 처음부터 끝까지 정말 자주 사용하는 자료구조 중 하나이다. 하물며 본과정 첫 과제인 Libft에서 명세에 따르면 Linked List의 구현과 연산 함수를 작성해야한다! 우선그때의 기억을 떠올려서 간단하게 C언어를 통해 Linked List를 구현해본 후, C++의 STL에 속한 Linked List 자료구조 사용법을 알아보자.
typedef struct s_node {
int data;
t_node *next;
} t_node
위 구조체는 Linked List의 한 노드의 구성이다. 한 노드는 데이터 영역과, 다음 노드의 주소 정보를 담고있는 포인터 영역으로 구분된다.
t_node *create_node(int data) {
t_node *new_node = (node *)malloc(sizeof(node)); // 1. 메모리 할당
new_node->data = data; // 2. 데이터 입력
new_node->next = NULL: // 3. next 초기화
return new_node;
}
void free_node(t_node *node) {
free(node);
}
우선, 힙 영역에 노드 크기만큼 메모리를 할당한다. 그 다음 인자로 입력받은 int 값을 통해 data를 초기화하고, 다음 노드를 가리키는 포인터 변수를 NULL로 초기화한다. 아직 어디에 연결할지는 모르는 상태이기 때문.
void append_node(t_node **head, t_node *new_node) {
if ((*head) == NULL) { // head가 NULL일 경우 new_node가 새로운 head로!
*head = new_node;
} else {
node *cur_node = (*head); // list를 순회하자.
while (cur_node->next != NULL) { // next를 통해 타고타고 넘어가 맨 마지막 노드에 도달한다.
cur = cur->next;
}
cur_node->next = new_node // 마지막 노드의 next를 new_node로 설정
}
}
// 노드 탐색_1 (n번째 순서의)
t_node *get_node_n(t_node *head, int n) {
t_node *cur = head;
while (cur != NULL && --n >= 0) {
cur = cur->next;
}
return cur;
}
// 노드 탐색_2 (data 탐색)
t_node *get_node_n(t_node *head, int data) {
t_node *cur = head;
while (cur != NULL) {
if (cur->data == data) {
break ;
}
cur = cur->next;
}
return cur;
}
void remove_node(t_node **head, int data) {
t_node *cur = *head;
t_node *prev = NULL;
if (cur == NULL) {
return;
}
// 첫 번째 노드가 삭제할 노드일 경우
if (cur->data == data) {
*head = cur->next; // 헤드를 다음 노드로 변경
free(cur); // 메모리 해제
return;
}
// 삭제할 노드를 찾기 위한 순회
while (cur != NULL && cur->data != data) {
prev = cur; // 이전 노드 저장
cur = cur->next; // 다음 노드로 이동
}
// 삭제할 노드를 찾지 못한 경우
if (cur == NULL) {
return;
}
// 이전 노드의 next가 삭제할 노드의 다음 노드를 가리키게 함
prev->next = cur->next;
free(cur); // 삭제할 노드의 메모리 해제
}
void insert_node(t_node **head, t_node *new_node, int position) {
t_node *cur = *head;
t_node *prev = NULL;
// 리스트가 비어있으면 new_node를 첫 노드로 삽입
if (cur == NULL || position == 0) {
new_node->next = *head;
*head = new_node;
return;
}
// 리스트 순회하여 삽입할 위치 이전 노드를 찾음
while (cur != NULL && --position > 0) {
prev = cur;
cur = cur->next;
}
// 새로운 노드를 삽입할 위치에 연결
if (prev != NULL) {
prev->next = new_node;
new_node->next = cur;
}
}
특정 함수에서 head를 이중 포인터 형식으로 전달하는 이유는 리스트의 첫 번째 노드 자체를 수정해야 할 가능성이 있기 때문이다.
head는 보통 리스트의 첫 번째 노드를 가리키는 포인터다. 만약 리스트의 첫 번째 위치에 새로운 노드를 추가하거나, 첫 번째 노드를 삭제할 때는 첫 번째 노드가 변경되어야 한다. 이때, head가 새로운 노드를 가리키게 하려면 함수 내부에서 head 자체를 수정해야 한다.
하지만, C 언어에서 함수는 인자로 받은 값을 복사해서 처리한다. 그래서 단순히 head를 함수에 넘기면, 함수 내부에서 아무리 수정해도 함수 밖의 실제 head는 바뀌지 않는다. 즉, 리스트의 첫 번째 노드를 바꿔야 하는 상황에서는 원하는 수정이 이루어지지 않는다.
이 문제를 해결하기 위해 이중 포인터를 사용한다. 이중 포인터는 head를 가리키는 포인터를 함수로 넘기는 방식이다. 그러면 함수 내부에서 head가 가리키는 위치를 직접 바꿀 수 있다. 이를 통해 리스트의 첫 번째 노드를 수정할 수 있게 된다.
예를 들어, 리스트의 맨 앞에 노드를 삽입하는 함수에서 이중 포인터가 필요한 이유는, 새로 삽입된 노드를 리스트의 첫 번째 노드로 설정해야 하기 때문이다. 이 작업을 하기 위해서는 head 자체를 수정해야 하므로, 이중 포인터로 head를 전달하는 것이 필요하다.
쉽게 말해, 리스트의 첫 번째 노드를 수정해야 할 때는 이중 포인터를 사용해서, 함수 안에서 실제 head가 바뀌도록 만들어야 한다.
#include <iostream>
#include <list>
int main() {
// std::list 선언 및 초기화
std::list<int> myList;
// 요소 추가 (push_back: 리스트의 끝에 추가)
myList.push_back(10);
myList.push_back(20);
myList.push_back(30);
// 요소 추가 (push_front: 리스트의 앞에 추가)
myList.push_front(0);
// 특정 위치에 요소 삽입 (iterator를 이용해 20 뒤에 25 삽입)
std::list<int>::iterator it = myList.begin();
std::advance(it, 3); // iterator를 세 번째 위치로 이동 (20 위치)
myList.insert(it, 25); // 20 뒤에 25 삽입
// 다시 출력
std::cout << "After inserting 25: ";
for (int val : myList) {
std::cout << val << " "; // 0 10 20 25 30 출력
}
std::cout << std::endl;
// 요소 삭제 (pop_front: 앞에서 삭제, pop_back: 뒤에서 삭제)
myList.pop_front(); // 앞의 0을 삭제
myList.pop_back(); // 뒤의 30을 삭제
// 최종 리스트 출력
std::cout << "After popping front and back: ";
for (int val : myList) {
std::cout << val << " "; // 10 20 25 출력
}
std::cout << std::endl;
return 0;
}
C++의 STL에서는 std::list라는 자료구조를 제공하여 Linked List를 쉽게 사용할 수 있다. std::list는 이중 연결 리스트로 구현되어 있으며, 삽입, 삭제 연산이 매우 효율적임! 이 자료구조는 앞쪽과 뒤쪽 양방향으로 노드를 탐색할 수 있다.
노드 하나에 int 뿐만 아니라 다양한 자료를 담고 싶다면, 원하는 구성의 구조체를 자료형으로 만들고, 그 자료형으로 list를 활용하면 된다.